{kind=link}
JohnBooty2 years ago
Thanks for that informative link. It's rare in these sorts of discussions.
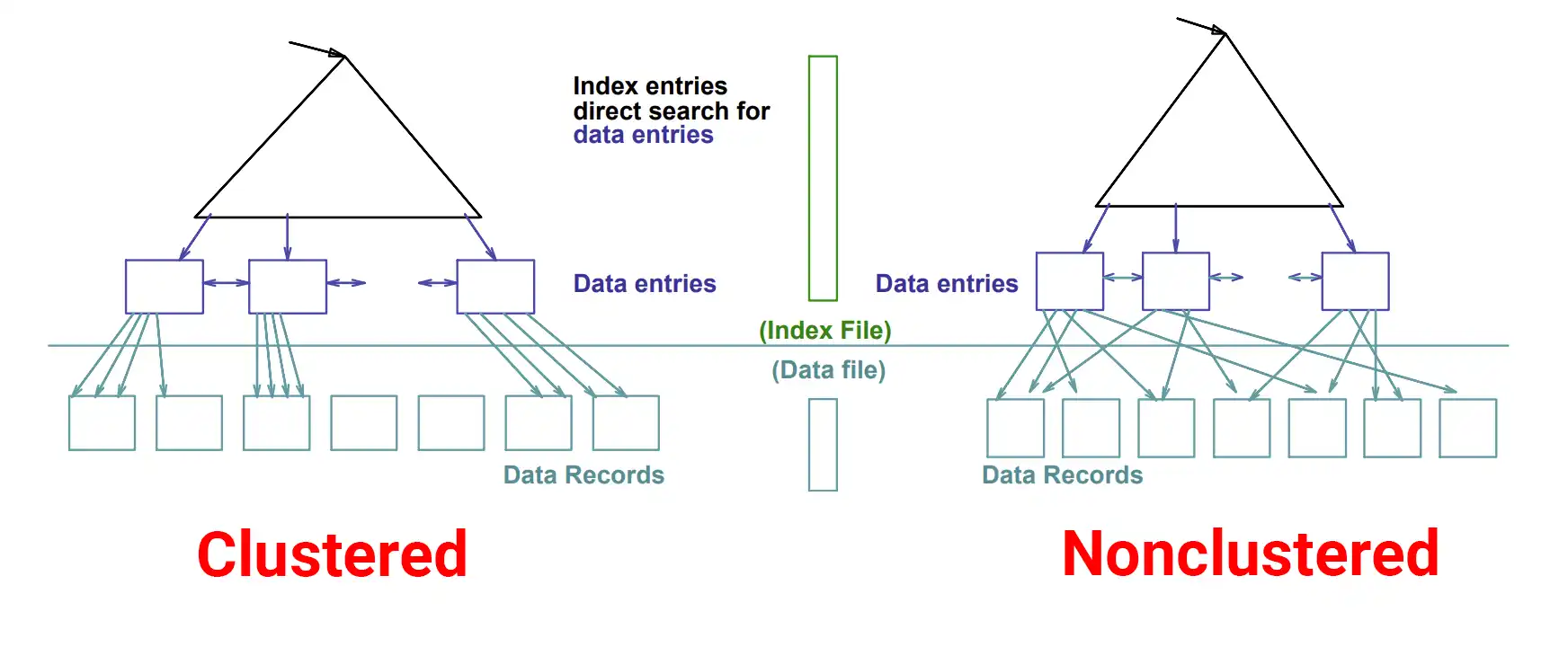
Sneak peek photo [1] (from [2]). Just imagine its literally 500-1000x more convoluted per B-tree leaf node. That's every Postgres table unless you CLUSTER periodically.
[1]: https://josipmisko.com/img/clustered-vs-nonclustered-index.w...
[2]: https://josipmisko.com/posts/clustered-vs-non-clustered-inde...
Mind boggling how many people aren't aware of primary indexes in MySQL that is not supported at all in Postgres. For certain data layouts, Postgres pays either 2x storage (covering index containing every single column), >50x worse performance by effectively N+1 bombing the disk for range queries, or blocking your table periodically (CLUSTER).
In Postgres the messiness loading primary data after reaching the B-tree leaf nodes pollutes caches and takes longer. This is because you need to load one 8kb page for every row you want, instead of one 8kb with 20-30 rows packed together.
Example: Dropbox file history table. They initially used autoinc id for primary key in MySQL. This causes everybodys file changes to be mixed together in chronological order on disk in a B-Tree. The first optimization they made was to change the primary key to (ns_id, latest, id) so that each users (ns_id) latest versions would be grouped together on disk.
Dropbox scaling talk: https://youtu.be/PE4gwstWhmc?t=2770
If a dropbox user has 1000 files and you can fit 20 file-version rows on each 8kb disk page (400bytes/row), the difference in performance for querying across those 1000 files is 20 + logN disk reads (MySQL) vs 1000 + logN disk reads (Postgres). AKA 400KiB data loaded (MySQL) vs 8.42MiB loaded (Postgres). AKA >50x improvement in query time and disk page cache utilization.
In Postgres you get two bad options for doing this: 1) Put every row of the table in the index making it a covering index, and paying to store all data twice (index and PG heap). No way to disable the heap primary storage. 2) Take your DB offline every day and CLUSTER the table.
Realistically, PG users pay that 50x cost without thinking about it. Any time you query a list of items in PG even using an index, you're N+1 querying against your disk and polluting your cache.
This is why MySQL is faster than Postgres most of the time. Hopefully more people become aware of disk data layout and how it affects query performance.
There is a hack for Postgres where you store data in an array within the row. This puts the data contiguously on disk. It works pretty well, sometimes, but it’s hacky. This strategy is part of the Timescale origin story.
Open to db perf consulting. email is in my profile.
This is not the same as "having a primary key", Postgres also has primary keys. It just stores the PK index separately from the bulk of the data.
Oracle also has primary keys, even if the order of the rows is different to the key order. In Oracle, when the rows are stored in the same order as the keys in the primary index, it is a special case and these tables are called IOT, index ordered tables.
The disadvantages of IOT are that inserts are slower, because in a normal table, the data is appended to the table, which is the fastest way to add data, and only the index needs to be reordered. In an IOT, the entire table storage is reordered to take the new data into account.
Select queries, OTOH, are much faster when using IOT, for obvious reasons, and this is what you describe in your comment.
If you use TEXT, BLOB, or JSON fields, even in MySQL, the actual data is stored separately.
You’re incorrect about IOT reordering the entire table at least wrt mysql. MySQL uses a B-tree to store rows, so at most it’s insertion sort on a B-tree node and rare b-tree rebalance. Most b-tree leaf nodes have empty space to allow for adding new data without shifting more than a few hundred other rows. Also, non-IOT tables also need to do a similar process to write to each of its indexes. Last, it’s sort of a tossup since if you’re appending to an IOT table frequently, the right edge of the B-tree is likely cached. (similarly for any small number of paths through the primary index B-tree). At worst Postgres heap will need to surface one new heap disk page for writing, although I’m sure they have some strategy for caching the pages they write new data to.
Sorry to spam this info! Glad to see we both love databases and I’m always please to see engagement about this topic!
Postgres also has other gotchas with indexes - MVCC row visibility isn't stored in the index for obvious performance reasons (writes to non-indexed columns would mean always updating all indexes instead of HOT updates [1]) so you have to hope the version information is cached in the visibility map or else don't really get the benefit of index only scans.
But OTOH, I've read that secondary indexes cause other performance penalties with having to refer back to the data in clustered indexes? Never looked into the details because no need to for postgres which we've been very happy with at our scale :)
[1] https://www.postgresql.org/docs/current/storage-hot.html
Wrt secondary indexes, yes and no. There is a cost to traverse a B-tree for point lookups. Also, foreign keys may now be composite keys if primary key is composite as in the Dropbox example.
If the secondary index is very different from the primary, it will be more expensive. However it’s pretty common to at least use a “user_id” as the first part of the primary key. This will make partial full scans a lot faster for queries regarding a single user; only need to scan that users data, and it comes at a 1-2 order of magnitude cheaper disk read cost. So you’d need a secondary index only if the data you need is spread across 1000s of pages (megabytes of data for a single user in one table) and you’re looking for only a handful of rows randomly located in that sequence.
Twitter is a characteristic case where you need many different clustered sets for the same data (tweets) to power different peoples feeds. I believe twitter just stores many copies of tweets in different clusters in Redis- basically the same as having a (author_id, ts) primary key tweets table and a (follower_id, ts) primary key feed table, both having tweet data inlined. If one clustered table isn’t enough, use two.
I will say: we kept every table we didn’t have to migrate for perf reasons in Postgres, and never regretted it.
Edit: and the index “fix” for Postgres doesn’t work often. Postgres will validate the row on disk, even if it’s in the index, if the page’s visibility map isn’t set. If you data isn’t write once, there’s a decent chance your page is dirty and it will still make the “heap” fetch.
Because you can only have a single clustered index, you're effectively paying for efficient range queries on a single clustering key by making all other queries slower.
This tradeoff may or may not be worth it depending on your query patterns. In my experience, you can often get away with adding some subset of columns to a non-clustered index to make it covering, and get efficient range queries without making a copy of the entire dataset.
And even with clustered indexes, as soon as you want a range query that's not supported by your clustered index, you're faced with the exact same choices, except that you have to pay the cost of the extra B-tree traversals.
Example: 80 bytes keys gives you branching factor of roughly 100. 10M rows and you can pack say 20 rows per page. That’s a 4GB table, give or take. That btree still only has 3 intermediate layers and primary data on a 4th layer. (Calculation is log(10M/20/0.75)/log(100)+1.) The first two layers take up less than a megabyte of ram and are therefore easily cached. So you wind up only needing 2 disk reads for the final two layers. Unless Postgres is caching the entire index for point lookups, it should come out about even.
Can’t find any resource saying that btree height exceeds 5, so I’m thinking it’s at worst 2x the (very small) disk read cost vs Postgres.
I'm now super interested in the perf aspects of running pg_repack. It would definitely require scratch storage space to be able to copy over the largest table in the DB (I'd guess 2.1x the largest table vs 2x the total DB size). I imagine repacking isn't as efficient as putting stuff into a B-tree. But I wouldn't expecting it to be anything like 50x worse like I portrayed above.
If you have a lot of write traffic, that log table will get really big, and pg_repack will have to do a lot of work to replay it. It's possible that the log table grows faster than pg_repack can replay it, which will cause it to never finish and eventually exhaust your storage space. You can also run into an issue where the log table never gets completely empty, and pg_repack never initiates that final lock and swap.
Partitioning helps a lot because it divides both the size of the tables and the write traffic to each table.